DynamoDB, Ten Years Later
 Ten years after the public availability of DynamoDB in 2012, and fifteen
years after the publication of the original Dynamo paper in 2007, the DynamoDB team published a
paper in Usenix ATC 2022 on how DynamoDB has evolved over its ten years of
operation. The paper covers several aspects of DynamoDB such as adaptation to customer access patterns, smarter capacity allocation, durability, correctness, and availability. In this post, I share some of points that I found
interesting in the paper.
Ten years after the public availability of DynamoDB in 2012, and fifteen
years after the publication of the original Dynamo paper in 2007, the DynamoDB team published a
paper in Usenix ATC 2022 on how DynamoDB has evolved over its ten years of
operation. The paper covers several aspects of DynamoDB such as adaptation to customer access patterns, smarter capacity allocation, durability, correctness, and availability. In this post, I share some of points that I found
interesting in the paper. Design Principles
- DynamoDB is a fully managed cloud service.
- DynamoDB employs a multi-tenant architecture. The key challenge here is to give a single-tenant experience to customers while enjoying hardware utilization and cost reduction of multi-tenancy.
- DynamoDB achieves boundless scale for tables.
- DynamoDB provides predictable performance. Predictable performance is of utmost importance to DynamoDB. It is a very important distinction of DynamoDB compared with previous solutions such as SimpleDB which was the first AWS database-as-a-service. Adding new features while keeping performance predictable is challenging. Previously, in this post, we saw how DynamoDB added support for ACID transactions while holding on to this design principle.
- DynamoDB is highly available. Four 9s for single-region, and five 9s for multi-region tables. Availability is calculated for each 5-minute interval as the percentage of requests processed by DynamoDB that succeed. Availability is measured both from the service and client perspective (via AWS internal clients or canary applications).
- DynamoDB supports flexible use cases. Multiple data, consistency, and isolation models.
Multi-Paxos instead of Leaderless Replication
Replication in the Original Dynamo
Nodes form a ring. Data items are distributed between these nodes according to the hash value of their keys. Each node is assigned a range. Given a key, we calculate its hash and then find its coordinator node based on the hash value and the hash ranges. Each key is hosted on the first node in the ring and replicated on the next N nodes.
Dynamo uses a leaderless quorum-based consistency approach. To write a value, the client sends its request to the coordinator node of the key. The coordinator applies the write locally and forwards the write request to the other N-1 replicas. It will then waits for W-1 of them to acknowledge the write before returning to the client. Similarly, to read, the coordinator sends the request to all N-1 replicas and waits for R-1 responses from them. Then, it returns the newest version out of R-1 responses heard from other replicas and its own version. When we use leaderless replication, we may have conflicts. To determine the newest version or detect conflicts, Dynamo uses vector clocks. I have talked about conflict resolution using vector clocks previously in this blog. In case of a conflict, Dynamo returns conflicting versions, letting the application decide to use which version.
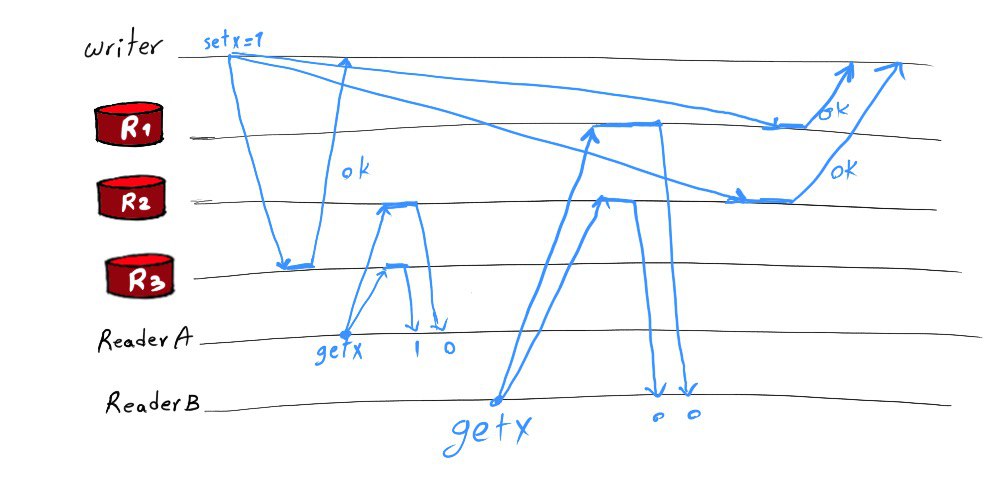 |
| Figure 1. An example of how linearizability may be violated even when read and write quorums are intersecting [4]. We have N=3, R=W=2. Reader B starts after reader A's request is returned, but the system appears as if reader B started before A; reader A reads the new value 1, while reader B reads the old value 0. |
Replication in DynamoDB
Yea, the idea of waiting for a quorum before returning to the client is shared in both approaches. However, there is a fundamental difference and that is the leaderless vs. leader-based natures of these methods. Scenarios like the one shown in Figure 1 never happen when using leader election; both readers A and B have to refer to the leader to read x, and this leader linearizes the operations. The original Leslie Lamport's Paxos uses majorities for two phases of Paxos (see this). However, majorities are not necessary, and similar to the R + W > N idea, only intersecting quorums are enough for Paxos to work [5].
Better Failure Detection
To avoid split brain during leader changes, DynamoDB uses leases. Specifically, a newly elected leader does not accept writes until the lease of the previous leaders is ended. That can be a few seconds. That means false leader failure detections are costly and must be avoided. Sometimes the leader is healthy and can communicate perfectly with a quorum of replicas. However, a single replica cannot verify the health of the leader. This situation is called a gray network failure in [1]. To prevent the affected replica from disrupting the system by starting a new leader election, DynamoDB uses the following approach: The affected replica first talks to other replicas to see what they think about the leader. Only if they also confirm that leader is dead, it starts the leader election. With this simple change, DynamoDB significantly minimized false leader failure detections.
In cases where the existing leader is intentionally going to be unavailable, e.g., for a deployment, it steps down as the leader by letting the other know, before deployment starts. This way, the new leader does not need to wait out the lease period, so interruption will be shorter.
Caching Metadata
Note that in case of a cache hit, the call to MemDS is done asynchronously, so we can go ahead and respond to the client without waiting for MemDS, so the benefit of having this local cache is to respond quickly for cache hits.
The calls to MemDS irrespective of a cache hit or cache miss results in constant traffic to MemDS. This constant traffic prevents bi-modal behavior and spikes in the system. With this design, it does not matter whether the cache is cold or not; MemDS always receives steady traffic from request routers.
The idea of constant work and its importance for avoiding cascading failures and unstability is discussed by AWS engineers in several blog posts. In [6], Colm MacCárthaigh compares systems with constant work to big coffee urns that don't scale up or down in response to traffic changes.

|
| "This is why many of our most reliable systems use very simple, very dumb, very reliable constant work patterns. Just like coffee urns." [6] |
In [7], Matt Brinkley and Jas Chhabra explain the addiction to cache and its problems:
"After a while, no one can remember life before the cache. Dependencies reduce their fleet sizes accordingly, and the database is scaled down. Just when everything appears to be going well, the service could be poised for disaster."
- Use cache to speed things up, but don't use it to hide work. Don't get addicted to it; always be prepared for situations where your cache is not efficient for some reason.
- Don't try to be smart by developing sophisticated services that quickly scale up and down in response to traffic. Be dumb! make your services do constant work.

Capacity Allocation
- 1 RCU: 1 strongly consistent read per second for items up to 4 KB in size.
- 1 WCU: 1 write per second for items up to 1 KB in size.
Note that both writes and strongly consistent reads must be done at the leader replicas as explained in the previous section. The RCU and WCU values set for a table are called provisioned throughput.
DynamoDB may partition a table for two reasons: 1) the table is too big and cannot be stored in a single machine, and 2) the desired throughput of the table cannot be provided by a single machine. The goal of the first type of partitioning is data scalability, while the goal of the second type is computation scalability.
Since DynamoDB is a multi-tenant system, it is crucial to isolate clients. To do that, DynamoDB used per-partition capacity allocation. For example, if the provisioned throughput of a table is 1000 RCUs, with two partitions each will have 500 RCUs. Thus, the storage nodes that host these partitions never allow the client to perform more than 500 RCUs on each storage node.
With per-partition capacity allocation, whenever DynamoDB splits a partition into two or more child partitions, the provisioned throughput of the parent was equally divided among the child partitions. This decision was based on the assumption that clients access the items of a table uniformly, so when we split the data equally, the required computation should also be split equally. However, this assumption proved to be wrong, and clients frequently have non-uniform access patterns. For example, a client may access a key range more than the other part of the table at a certain time.
Throughput Dilution and Unexpected Throttling
Smarter Capacity Allocation
The following are approaches DynamoDB used to improve capacity management.
Bursting: Let partitions tap into unused capacity available on the node. Thus, with bursting, DynamoDB lets a partition consume capacity more than its allocation, as long as enough unused capacity is available on the node. The problem with bursting is that it is only useful for short-term bursts.
Adaptive Capacity: When a table is throttled while its consumed throughput is not exceeded its provisioned throughput, adjust the capacity allocation of the hot partitions to let them spike for a longer time. With adaptive capacity, a partition can have longer bursts compared with the bursting using the unused capacity approach. When a client's consumption exceeds the table provisioned throughput, DynamoDB reduces the capacity allocation, because when the client is exceeding its provisioned throughput, it is acceptable to throttle its request. A big disadvantage of this method is that it is a reactive approach, i.e., unwanted throttling should first happen for this mechanism to be triggered.
DynamoDB prevents a single partition from consuming all or a significant portion of the resources on a storage node. Thus, the per-partition usage is capped. However, note that this limitation is not the same as static per partition allocations that we used to simply divide table capacity by the number of partitions. This per-partition limitation is more like a defense mechanism rather than an admission control mechanism because the admission control is done at the global level by GAC.
Yea, exactly. That's why DynamoDB uses the next approach (balancing) in conjunction with GAC.
Splitting: Split a hot partition to make it more manageable. DynamoDB splits based on the key usage distribution in this case instead of simply cutting in the middle. DynamoDB avoids splitting in two cases: 1) if a single key is hot, and 2) the client is accessing keys in range. In these cases, splitting won't help.
On-demand provisioning: Since customers usually either underprovision or overprovision, with on-demand tables, customers let DynamoDB adjust provisioned throughput based on the actual consumption.
Durability
The following are some of the methods that DynamoDB uses to guarantee that data is never lost or corrupted after being committed.
Write Ahead Log (WAL): The WAL is replicated and periodically archived to S3.
Checksums: Every log entry, message, or log file is protected by checksums. When archiving to S3, all these checksums are checked. Checksums are not used only for data transmission, data at reset is also continuously verified using these checksums.
Backup and restores: The goal of backup is to protect customers from their logical errors. DynamoDB periodically snapshot tables. Together with archived logs, these snapshots can be used to provide point-in-time restores.





Comments
Maybe a similar question: when the leader receives a write request, does it first write it to its WAL, and then forward the request to the replicas? If so do we write to the WAL if we receive acks from replicas?
Post a Comment