Calvin is a transaction scheduling and replication protocol that provides
distributed ACID transactions for partitioned and replicated systems. In its
heart, Calvin relies on a locking mechanism that unlike 2PL is
deterministic. This determinism removes the need for an atomic commit
protocol (e.g. 2PC) which leads to a significantly smaller contention
footprint of distributed transactions.
Both Calvin and Spanner introduced in
2012 solving the same problem with completely different approaches. Thus, it
is interesting to compare them side-by-side. In this post, however, we focus on Calvin. You can refer to
this post to learn more about Spanner.
The Idea: Remove nondeterminism, get rid of 2PC!
Suppose we have a single-node database without any partitioning or
replication. As we said in
this post, one way to achieve strict serializability is through actual serial
execution, i.e. to execute transactions in a single thread and one-after-another.
This removes all sorts of conflict between transactions and provides the
highest level of isolation. However, it does not scale, because we are limited
to a single thread. Each transaction has to wait for the transaction before
it, even when transactions are completely unrelated, accessing
different data. To increase the scalability, we want to be able to run
unrelated transactions in parallel while running conflicting transactions in
the serial order. This is exactly what 2-Phase Locking (2PL) provides. Thus,
2PL is great! it opens the door for parallelism without sacrificing the serializability.
For most of today's applications, a single-node database is not enough. To
achieve higher scalability and availability, we have to both partition and replicate their database. In a partitioned database, a single transaction may
access data hosted in multiple shards. How can we achieve serializability for
a multi-shard transaction? Can't we send our transaction to all involved
shards each running 2PL? Unfortunately, no. The main problem is the nondeterminism of 2PL. For example, if two transactions
accessing the same lock are executed at the same time, it is not determined
which of them will run first. It is also possible that 2PL abort one of these
transactions to avoid deadlock (see
this post). Suppose T1 and T2 are both multi-shard transactions. If we simply send
them to the shards and let them run 2PL independent of each other, we might
end up being in a bad situation: 1) the order of execution might be different
between the shards, potentially violating the isolation, or 2) a
transition may commit on one shard and abort on the other, violating the atomicity.
As you can see, we cannot simply send our transaction to all shards and let
them independently run 2PL due to nondeterminism of 2PL. To solve this issue, we can
use an atomic commit protocol such as 2-Phase Commit (2PC). By coordinating
all shards involved in a transaction with 2PC and running 2PL on each of them
we can guarantee serializability for our distributed transaction. This is exactly what
Spanner does. You can refer to this post to learn more about it.

|
|
Figure 1. 2PL alone cannot guarantee isolation for distributed
transactions (left). 2PC+2PL guarantees isolation and atomicity for
distributed transactions (right).
|
So the problem solved! using 2PC+2PL we achieved distributed serializability.
Yes, but there is a problem: in 2PL, while a transaction is holding the locks,
all other transactions requesting the same lock must wait. In a single-node
database, the transaction manager gets the locks, quickly execute the
transaction, and release them. So, it is fine. In a partitioned and
replicated system, the transaction manager has to wait for two other things: 2PC
and replication. In other words, although the local shard is done with the
transaction and is ready to release the locks, it cannot, because before doing that, it has to
make sure enough replicas in all shards participating in the transaction have received the transaction and all shards are OK with transaction to commit. These additional delays increase the time that a
transaction holds the locks. This time is known as the
contention footprint [1]. In a transactional system, we like to minimize
the contention footprint as much as possible.
The large contention footprint of distributed transactions with 2PC+2PL is mainly due to the nondeterminism of 2PL. If only somehow we could get rid of
this nondeterminism while simultaneously guaranteeing serializability and
keeping parallelism that would be awesome. The good news is we can! Using
deterministic locking we can achieve determinism, serializability, and
parallelism. We will cover the details of deterministic locking in this post,
but the general idea is to define a global order for transactions using
basically a single thread of execution upfront and use this order to decide which
transaction should execute first.
 So how deterministic execution is different from the actual serial
execution?
So how deterministic execution is different from the actual serial
execution?
In the actual serial execution, a single thread orders AND execute the
transactions. In the deterministic execution, a single thread orders the
transactions, but the execution could be parallel when doing so does not violate the
global order.

|
Figure 2. The difference between actual serial execution (left) and
deterministic execution (right)
|
Once we get rid of the nondeterminism of 2PL, we can get rid of 2PC as well.
Now with deterministic locking, we can simply send our transactions to their
corresponding shards in the global order. Each shard runs the deterministic
locking and guarantees the global order is preserved while executing transactions in parallel when possible.
But what about shard failures? If one of the shards fails, then the
transaction will be applied halfway though.
We will go through the details of Calvin below, but there is no issue with shard failure, as we make sure all transactions are durable by appending them to a replicated log upfront. This log can be considered as a write-ahead log for the system. Thus, this log both define the order and guarantee durability and atomicity.
The need to globally order all transactions prevents us from using interactive
transactions, because if we use interactive transactions, once the
transaction starts all future transactions must wait for it to finish which is
not acceptable. Thus, in Calvin, transactions must be in the form of
stored procedures. A stored procedure is a piece of code that defines
the logic of the transactions. The transaction can read some data and based on
that update some other data, but no logic can run on the client-side. Instead,
the client submits its logic in a single shot and the database executes
it.
Design
After understanding Calvin's idea, let's see how it actually handles
transactions. Figure 3 shows the overall architecture of Calvin. Calvin
consists of three layers which we discuss below.

|
|
Figure 3. The Architecture of Calvin [1]
|
Sequencing Layer
We saw that Calvin needs to define a global order for all transactions. The
easiest way to do that is to have a single process with a single thread that
receives transactions one by one and orders them. Obviously, having only a
single thread has scalability and availability issues. The sequencing layer of
Calvin is responsible to provide the global ordering of transactions just like
the single thread while providing horizontal scalability and higher
availability.
As it is shown in Figure 3, each node in a Calvin cluster has a sequencer
process. First, consider the case where we don't have any replication. The sequencers divide the time in terms. In each term, sequencer share transactions that they have received with each
other. Then, they use round-robin to define the order. For example, suppose, in the
first term sequencers 1, 2, and 3 receiver transaction T1, T2, and T3,
respectively. Each sequencer orders them as T1, T2, T3. In the next, term,
they receiver T4, T5, T6. This time, sequencers order them as T5, T6, T4.
Thus, the global order of transactions so far is T1, T2, T3, T5, T6, T4. This
way, all sequencers can receive requests while guaranteeing a global
order.
Now consider the case where we have replication. In this case, we can choose
between synchronous or asynchronous replication. In asynchronous replication,
one replica is the primary replica and run exactly as we explained above.
Other replicas will receiver the transactions asynchronously and apply them.
Thus, all requests must go to the primary replica. The advantage of this
method is since replication is asynchronous, the clients don't need to wait
for the replication. Thus, it is faster. However, handling failure is
complicated. In synchronous replication, we have to basically use a consensus
protocol such as Paxos to make sure writes are replicated to enough replicas
before moving forward and apply them. In any case, replication does not change
the round-robing mechanism explained above; in each term, sequencers order
transactions proposed by each shard in a round-robin fashion. Note that to
amortize the cost of consensus and communications, sequencers batch together all transactions received in each term and then share the batches with other replicas and sequencers. The Calvin paper suggests each term to be 10 ms to allow
sequencers to batch transactions.
Note that in a replicated system, we need to make sure all replica mutate the
data in the same way, otherwise replicas become inconsistent with each other.
In Calvin, each transaction will be executed as a stored procedure by each
replica. Although they all execute the same logic, any source of
nondeterminism in the logic can lead to the divergence of the replicas. For
example, when we have a random number in the transaction code, each replica may
end up producing different random numbers. In addition, when we call
the system time in the transaction code, it is quite likely different replicas
end up getting different values. All of these possibilities must be eliminated
when we want to let each replica execute the transaction's logic
independently. Thus, before appending a transaction to the replicated log, a
preprocessing step must be taken by the sequencers to remove these sources of
nondeterminism. Specifically, sequencers analyze transaction code and
pre-execute any nondeterministic code.
Scheduling Layer
Each sequencer submits the next batch of the transactions to the scheduler on
the same node. The schedulers use deterministic locking for concurrency
control. As explained above, unlike 2PL, deterministic locking never aborts
any transaction and guarantees that the global order of transaction is
respected while allowing parallel execution. Let's see how it works.
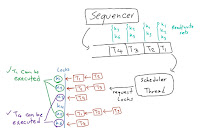
Figure 4 shows an example of deterministic locking. The sequencer as its
output provides a log which is a sequence of transactions. There is a single
scheduler thread that receives these transactions. There is a lock table that
maps each object to a list of requesting transactions. Whenever the scheduler
thread reads a transaction from the transaction log, it adds a lock request
for all keys in the read and write sets of the transaction.
This is why Calvin needs to know the read and write sets of a transaction
before executing a transaction. Transactions competing for the same lock, acquire the lock based on the FIFO
order of the queue of the lock. A transaction is ready to be executed once it
obtained all the locks that it needs. Once the transaction is done, it will be
removed from the lock table, allowing all transactions in the queue to acquire
it. Note that transactions that do not compete for a common lock will never
block each other, so they can be executed in parallel. Another interesting
part is, unlike 2PL, with deterministic locking there will never be any deadlock.
 |
Figure 4. Deterministic locking. T1 and T4 can be executed. T2 and T3 will be blocked.
|
Storage Layer
Once a transaction is ready to be executed, one of the executor threads can execute
it. We can have as many executor threads as we want. A transaction may read or
write keys in multiple shards. Thus, a executor in a shard may not be able to
independently execute the transaction, because to execute the logic of the transaction it needs to read keys hosted on the other shards. For example, consider transaction T that reads value x hosted on shard A and updates the value of y hosted on a shard B to the value of x plus one.
The executor threads in different shards collaborate with each other to execute a transaction. Specifically, each execution thread works as follows:
-
Read/write set analysis: Each execution thread first checks the
read and writes sets to see what shards are involved in the transaction.
Each node that writes a value for a transaction is called an
active node for that transaction. In the example above, the execution
thread on shard A sees that transaction T is writing a value on shard
B.
-
Read local objects: Each execution thread reads keys hosted on the current node. In the example above, the execution thread on node A
reads the value of x.
-
Serve remote reads: Each execution thread sends what it has read
locally to all active nodes of the transaction. In the example above, the
execution thread on node A sends the value of x to its peer on node
B.
-
Collect remote reads: If the execution thread is running on an
active node, it waits until it receives all the reads from other nodes.
In the example above, the execution thread on node B blocks until it receiver the
value of x from its peer on node A.
-
Execution: Once an active node got all the reads, it executes the
transaction. In the example above, the execution thread on B unblocks once it
received the value of x, and updates the value of y.
Complications
Dependent Transactions
As we said, Calvin needs to know the read and write sets of a transaction
before its execution. However, some times it is not possible to know the
full read and write sets before executing the logic of the transaction. For
example, a transaction may first need to read a certain object and based on
its value, it decides to update certain keys. How does Calvin support these kinds of transactions? Such transactions are called dependent transactions [1]. Calvin supports dependent transactions by a 2-phase scheme. In phase 1, it runs a query that performs all the necessary reads to decide the
full read and write sets of the transaction. To fast-track this phase,
Calvin reads the keys with an in-expensive, low-isolation, and unreplicated
read query called reconnaissance query. Note that normal read-only
transactions must go through the normal process for read-write transactions,
i.e. they will be batched at the sequencer, appended to the replicated log,
scheduled, and finally executed by execution threads. They guarantee
isolation and recency of the data, but they are slow.
The reconnaissance query bypasses these steps, so it is much faster,
but the value that we read with a reconnaissance query might be
invalidated when we want to execute the transaction. Thus, in phase 2 of
running dependent transactions, the transaction will be restarted if we find
out read values in phase 1 have changed. As you can imagine this approach may cause some transactions to starve, i.e. never be
executed, if their dependencies get updated frequently [2].
How strict serializability is guaranteed for dependent transactions when
we may retry them. Suppose we have two transactions T1 and T2 as
follows:
T1 {
read(x)
if (x == 1)
write (y)
else
write (z)
}
T2 {
read(y)
}
T1 is a dependent transaction with a dependency on x, and T2 is a read-only
transaction. Suppose a client first submits T1 and then T2. If T1 gets restarted due to an update to x between
phase 1 and phase 2 explained above, the order of T1 and T2 on the log will
be changed such that T2 will be executed first and then T1. Thus, T2 won't see the effect of T1 on y. Doesn't this
violate the strict serializability?
No, it does not violate strict serializability. Strict serializability, more
specifically the linearizability part of it, concerns about non-concurrent
transactions, i.e., T and T' when T' starts after T is committed.
Thus, in your example, only because T2 started after T1 does not require T2 to see the effect
of T1. For non-dependent transactions, Calvin can return success to the client
once it successfully appended the transaction to the replicated log. For the
dependent transactions, on the other hand, Calvin does not return success to
the client until it made sure the transaction can be executed. If the read of phase 1 explained above are not valid, Calvin restarts the transaction by
appending it to the log again. Once phase 2 is successful, we can return success to
the client. In any case, when the client receives success, it can consider its
transaction committed.
Disk Access Bottleneck
Consider two transactions T1 and T2:
T1 {
read x1, x2, ..., x100
write y
}
T2 {
read y
}
Let's compare the behavior of 2PL and Calvin's deterministic locking. In 2PL,
T1 requests lock for each object it wants to read or write gradually as the transaction is being executed. Suppose, it takes a long time to read x1 to
x100. In 2PL, it possible for T2 to go ahead and read the value of y while T1
is waiting for the disk to read x1 to x100. Thus, with 2PL the store is able
to switch the order of T1 and T2 to achieve better throughput. On the other
hand, in Calvin, the store locks all the keys touched by the T1 including y as
soon as T1 starts. Thus, T2 must wait for T1 to finish. This is a major
challenge for Calvin when the contention is high and data access is slow, e.g.
when data is stored on disk.
Calvin's solution is to deliberately delay transactions based on their disk
access, i.e. when a sequencer sees that T1 needs to make many disk accesses, it
deliberately delays appending this transaction to the replicated log.
Meanwhile, it sends requests to the storage layer to make the disk access and
load data to memory. Thus, the sequencer needs to estimate how much it must
delay appending the transaction to the log. However, that is not easy! It will be either underestimated or overestimated. If the sequencer underestimates that time, T1 might be executed while its data is not read thereby blocking
other transactions which leads to lower throughput. If the sequencer overestimates this time, the latency will increase for T1. Both of them are not desired.
In Summary,
-
Calvin uses a replicated log at the front of the system that orders transaction requests and plays the role of a WAL for the system providing atomicity and durability. Before adding a transaction to this log, Calvin removes any
source of nondeterminism (e.g. reading system time or generating random
numbers) from the transaction logic.
-
Calvin removes the need for 2PC by removing the nondeterminism caused by
2PL by replacing 2PL with a deterministic locking on each
participant.
- By removing the nondeterminism Calvin avoids 2PC for distributed transactions.
- Calvin only support transactions in the form of stored procedures.
-
The deterministic locking requires to know the whole read/write set of the
transactions. Thus, supporting transactions that need to first read to
figure out their final read/write set is challenging in Calvin.
-
Calvin has to pick between transaction latency or throughput while dealing
with high contention and slow disk access.
References
[1] Alexander Thomson, Thaddeus Diamond, Shu-Chun Weng, Kun Ren, Philip
Shao, and Daniel J. Abadi. "Calvin: fast distributed transactions for
partitioned database systems." In Proceedings of the 2012 ACM SIGMOD
International Conference on Management of Data, pp. 1-12. 2012.
[2] Alexander Thomson, and Daniel J. Abadi. "The case for determinism in database systems." Proceedings of the VLDB Endowment 3, no. 1-2 (2010): 70-80.








Comments
Post a Comment