Dual Data Structures
In multi-threaded programs, threads typically communicate with each other by calling the API of a shared data structure. It is challenging to keep a data structure in a sound state when using it concurrently by several threads. There are many blocking and non-blocking solutions for this problem. In this post, we want to see how dual data structures deal with this problem.
Before moving forward; with powerful hardware available today, do we need parallelism? Can't we just stick to a single thread and make our life easy?
The hardware improvement has significantly slowed down since 2004 (see
chart below from [1]). To keep improving the processing power, the
manufacturers have kept adding more cores since then. So if the processing
power of two decades ago is enough for you, and you are OK wasting resources
that are available to you today via multiple cores, yea, you can avoid
parallel processing. However, to fully utilize your modern hardware, you have
no choice but to embrace parallelism.

Data Structures and Concurrency
- Let threads concurrently access the data structure
- Provide an illusion of sequential access
Thread 1 {sees head and tail are Asets head and tail to NULL}
Thread 2 {sees tail is Asets A.next to Bsets tail to B}

|
| Sketch 1. A queue with a single entry and our desired end state after a dequeue and an enqueue. |
Thread 1: sees head and tail are AThread 2: sees tail is AThread 2: sets A.next to BThread 2: sets tail to BThread 1: sets head and tail to NULL

Synchronization
To solve the above problem, one way is to guarantee atomicity for the operations using locks. Specifically, each thread first obtains an exclusive lock on the data structure, performs its operation, and finally releases the lock. We can do that using synchronize blocks or functions in Java. This approach does not perform well, especially if the thread holding the lock is preempted by the OS scheduler before finishing the operation and releasing the lock.
Non-blocking Queue
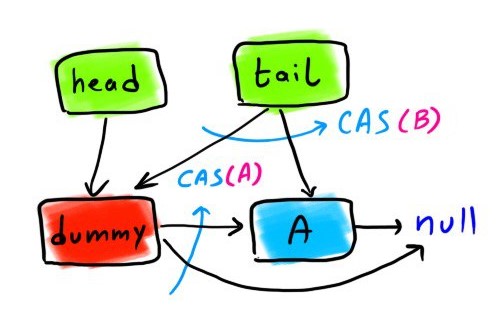
There are many non-blocking data structures that avoid locks while letting multiple threads concurrently execute their operations on the data structure. Typically these data structures use some synchronization primitives supported by hardware such as Compare-And-Swap (CAS) operation. A non-blocking queue (known as M&S queue) using CAS is presented in [2]. In this data structure, we have a dummy node that is defined to be the node whose next pointer points to the first actual node inserted to the queue. The head pointer of the queue always points to the dummy node. Initially both head and tail pointers point to the dummy node. After enqueuing to the queue, the head pointer still points to the dummy node, and the tail pointer points to the newest item added to the queue.

|
| Sketch 3. Structure of a M&S non-blocking queue |
To enqueue, we basically wants to do this:
- Set the current tail->next to the new node
- Set tail to the new node.
- We set the tail->next to the new node only if tail->next is NULL. If another thread managed to enqueue before this thread, the CAS operation returns failure and we have to repeat.
- We also set the tail of the queue to the new node, only if the tail has not changed. For example, if after setting the next pointer of the former tail, and right before updating the tail, another thread enqueued another node and updated the tail, the CAS fails and the first thread does not update the tail anymore.
boolean CAS(variable_to_bet_set, expected_value, new_value)enqueue(value) {node = new node()node->value = valuenode->next = NULLwhile (true) {old_tail = tailold_next = old_tail->nextif (tail == old_tail) {if (old_next == NULL) {// if CAS fails, it means another thread has enqueued, we have to try againif (CAS(old_tail->next, NULL, node)) (A)break} else {//tail must be fixedCAS(tail, old_tail, old_next)}}}//we update the tail if tail is still the one we saw. Otherwise, no action is neededCAS(tail, old_tail, node) (B)}
 |
| Sketch 4. Enqueueing a non-blocking queue. To update the next pointer of the former tail and updating the tail itself, we use CAS. |
- Set the returned value to head->next (Note that head is dummy node.)
- Set head to the head->next.
deueue(returned_value) {while (true) {old_head = head //dummy nodeold_tail = tailold_next = head->next //the actual front of the queueif (head == old_head){if (head == tail) {if (old_next == NULL) {//queue is empty and no clean-up needed.return FALSE}//queue is NOT really empty and the tail must be fixedCAS(tail, old_tail, old_next)} else {//critical to read value of old_next before the updating the headreturned_value = old_next->value//if CAS fails, it means another thread has dequeued a new entry before this thread,//we have to try againif (CAS(head, old_head, old_next)) (A)break}}}free(old_head)return TRUE}
 |
| Sketch 5. Dequeuing a non-blocking queue. We update the head pointer with CAS. The former head is the new dummy node pointed by the head pointer. |
Dequeuing an Empty Queue
No matter whether a data structure uses locks or it is lock-free, when a thread wants to read from the data structure and it does not have any data ready, the thread must wait. A typical situation that this might happens is when we have a pool of worker threads taking jobs from a queue. The worker threads will be blocked when the queue is empty.
Let's see how we can deal with lack of data. When we use locks, we can put a reader thread to sleep and wake it up when data is ready. However, we cannot do that with a non-blocking data queue, as we don't use any lock. Thus, a common approach is to use a busy-wait loop.
do { t = q.dequeue() } while (t == NULL)// process t
- It introduces unnecessary contention for memory and communication bandwidth that causes performance degradation
- It does not provide fairness; suppose Thread 1 and Thread 2 both wants to dequeue and Thread 2 calls dequeue after Thread 1. With this approach, there is no guarantee that Thread 1 will gets its data before Thread 2.
Dual Data Structures

|
| Sketch 6. The idea of dual data structures is to hold both data and anti-data |
dequeue() {node = new node() //it is a reservationnode->request = NULLnode->isRequest = truewhile (true) {old_tail = tailold_head = headif (old_tail == old_head || tail.isRequest) { (A)//In this case, (possibly) either queue is empty or no data is available.//We like to enqueue a reservation, but we need further checks before that.old_next = tail->nextif (tail == old_tail) {if (old_next != NULL) {//The tail must be fixedCAS(tail, old_tail, old_next)} else if (CAS(tail->next, next, node)) {//Either queue was empty or no data exists, so we went ahead and//succeeded in enqueuing the new reservation using CAS. Now, we try to update the tailCAS(tail, old_tail, node)//fixing the head if necessaryif (old_head == head && head->request != NULL) {CAS(head, old_head, head->next)}//Note that we spin on the OLD tailwhile (old_tail->request == NULL)old_head = headif (old_head = old_tail) {CAS(head, old_head, node)}result = old_tail->request->valuefree(old_tail->request)free(old_tail)return result}}} else { (B)//In this case, (possibly) we have a data available.//So we try to dequeue it instead on adding a new reservationold_next = old_head->nextif (old_tail == tail) {result = old_next->vale //note that the head is dummyif (CAS(head, old_head, old_next) {free(head)free(node)return result}}}}}
enqueue(value) {node = new node()node->value = valuenode->next = NULLnode->request = NULLnode->isRequest = falsewhile (true) {old_tail = tailold_head = headif (old_tail == old_head || !tail.isRequest) { (A)//In this case, (possibly) either queue is empty or no request is waiting//We like to enqueue new data node, but we need further checks before that.old_next = tail->nextif (tail == old_tail) {if (old_next != NULL) {//The tail must be fixedCAS(tail, old_tail, old_next)} else if (CAS(tail->next, next, node)) {//Either queue was empty or no request exists, so we went ahead and//succeeded in enqueuing the new node using CAS. Now, we try to update the tailCAS(tail, old_tail, node)//no matter CAS is successful or not we return herereturn}}} else { (B)//In this case, (possibly) we have a waiting request.//So we try to satisfy that instead of enqueuing a new node.old_next = old_head->nextif (old_tail = tail) {req = old_head->requestif (head == old_head) {//If head request (req) is NULL, i.e., it is not yet satisfied, we set it to the new node.success = (!req && CAS(old_head->request, req, node))//Pop the head no matter we consumed the new node or not.//In case we don't consume the new node, here we are basically doing cleanup left by another threadCASE(head, old_head, old_next)//We returned if we actually satisfied a request and consumed the new node.//Otherwise we repeat the loopif (success) return}}}}}
Java Implementations
ConcurrentLinkedQueue is a non-blocking queue based on the non-blocking queue explained above from [2].
SynchronousQueue is the synchronous version of the dual queue. With a normal dual queue explained above, only a dequeue may be blocked due to lack of available data. With a synchronous queue, on the other hand, an enqueue may also be blocked due to lack of a request. Thus, with a SynchronousQueue, producers and consumers pair up to synchronously produce and consume data.
Exchanger is another dual data structure implemented in Java standard library based on [4]. With exchanger, there is no distinction between producer and consumer. Instead, any thread is both producer and consumer, so threads pair up to exchange data with each other.
Summary
References
[2] Maged M. Michael, and Michael L. Scott. "Simple, fast, and practical non-blocking and blocking concurrent queue algorithms." In Proceedings of the fifteenth annual ACM symposium on Principles of distributed computing, pp. 267-275. 1996.
[3] William N. Scherer, and Michael L. Scott. "Nonblocking concurrent data structures with condition synchronization." In International Symposium on Distributed Computing, pp. 174-187. Springer, Berlin, Heidelberg, 2004.
[4] William N. Scherer III, Doug Lea, and Michael L. Scott. "A Scalable Elimination-based Exchange Channel." SCOOL 05 (2005): 83.
[5] Michael Scott, "Dual Data Structures"(Hydra2019) https://2019.hydraconf.com/2019/talks/lnhqpq8cz5kzgjmhlqpic/





Comments
Post a Comment